
Amazon S3 Vectors が GA — OpenSearchとの使い分けとRAGのコスト最適化
2025年12月にGAしたAmazon S3 Vectorsを、AWSフリーランス実務の視点で解説。ベクトルをネイティブ保存できる初のオブジェクトストレージの位置づけ、3要素の料金構造、次元数や制限、OpenSearchとの使い分け・ハイブリッド設計までRAG実装目線で整理します。
- #Amazon S3
- #S3 Vectors
- #ベクトル検索
- #RAG
- #OpenSearch
- #生成AI
RAGや生成AIアプリを作っていると、一度はぶつかるのが「ベクトルストアを何にするか」という選定の悩みではないでしょうか。専用のベクトルDBは高い、かといって OpenSearch はオーバースペックかもしれない。そんな迷いに、もう一つの選択肢が加わりました。Amazon S3 Vectors です。2025年12月にGA(一般提供開始)した、ベクトルをネイティブに保存・検索できる「初のオブジェクトストレージ」です。
この記事では、S3 Vectors の立ち位置から料金の考え方、次元数などの制限、そして本題の OpenSearch との使い分け/ハイブリッド階層設計 まで、「自分のワークロードならどれを選ぶか」を判断できるよう整理してみましょう。なお「ベクトル検索」とは、文章や画像を数値の並び(埋め込み=embedding)に変換し、意味の近いものを類似度で探す検索のことです。
S3 Vectors とは — 何を解決するか
S3 Vectors は、AWSの言葉を借りれば「ベクトルのネイティブな保存・クエリをサポートする初のクラウドオブジェクトストレージ」です。ふだんファイルを置いているあの S3 に、ベクトル専用のバケット(vector bucket)を作り、ベクトルを置いて類似検索ができる、というイメージですね。
解決するのは、ひとことで言えば ベクトル保存のコスト障壁 です。これまで大量のベクトルを保持するには専用のベクトルDBや常時稼働の検索クラスタが必要で、データ量が増えるほどコストがかさみました。S3 Vectors は専用インフラのプロビジョニング(事前のサーバー確保)が不要で、S3にベクトルを置くだけで使えます。
得意なのは「大量・長期・低頻度アクセス」のベクトルです。巨大なナレッジの意味検索、コスト制約のあるRAG、AIエージェントの長期記憶といった領域ですね。秒間に大量のクエリをさばく用途ではなく、「たくさんのベクトルを、安く、長く持っておく層」だと捉えると位置づけがすっきりします。なお Amazon Bedrock Knowledge Bases のベクトルストアとしても利用でき、Bedrock で組むRAGの保存層に選べます。
スケール・性能・実務で効く制限
GAで変わったのは、まずスケールです。プレビュー時の約40倍に伸び、1インデックスあたり最大20億ベクトルまで扱えるようになりました。性能面は、低頻度のクエリで1秒未満、高頻度なクエリで約100ミリ秒以下のレイテンシ(応答にかかる時間)。距離関数はコサインとユークリッドに対応します。
設計時に引っかかりやすい主な制限を表にしました。
| 項目 | 値(実務での意味) |
|---|---|
| 次元数 / ベクトル | 1〜4,096 ← 使う埋め込みモデルの出力次元がこの範囲か要確認 |
| ベクトル数 / インデックス | 最大 20億 |
| ベクトルインデックス数 / バケット | 最大 10,000 |
| メタデータ合計 / ベクトル | 最大 40KB(filterable+non-filterable) |
| filterable メタデータ / ベクトル | 最大 2KB ← 絞り込み用メタデータは軽量に設計 |
| メタデータキー数 / ベクトル | 最大 50 |
| クエリの Top-K(返却件数) | 最大 100 |
| PutVectors+DeleteVectors / 秒・インデックス | 最大 1,000 |
とくに注意したいのは2点です。ひとつは次元数の上限4,096。お使いの埋め込みモデル(Titan / Cohere / OpenAI系など)の出力次元がこの範囲か、最初に確認しましょう。もうひとつは filterable メタデータの2KB制約。「filterable メタデータ」とは検索時の絞り込み条件に使えるメタデータで、容量上限があるためフィルタ設計は軽量に保つのがコツです。
GA状況と料金 — 3要素の従量課金
S3 Vectors は 2025年12月2日にGAし、プレビュー時の5リージョンから14リージョンへ拡大しました。なお、対応リージョンに東京(ap-northeast-1)が含まれるかは本稿執筆時点で確証が取れていないため、利用検討時は公式のリージョン・クォータのドキュメントで必ずご確認ください。
料金は 3要素の従量課金 です。考え方を押さえると見積もりの当たりがつきます。
| 課金区分 | 参考値(2026年6月時点・参考値) |
|---|---|
| ベクトルストレージ | $0.06 / GB・月(ベクトルデータ+メタデータ+キーを含む論理量) |
| PUT(アップロード) | $0.20 / GB(アップロードした論理GB) |
| クエリ(APIリクエスト) | $2.5 / 100万クエリ(API calls) |
| クエリ(データ処理) | インデックスサイズに応じた $/TB 課金。10万ベクトルを超えると単価が下がる構造。具体額は公式料金ページで要確認 |
上記はあくまで 2026年6月時点の参考値 です。AWSの料金は改定されうるので、見積もり時は必ず公式のS3料金ページで最新の値を確認してください。とくにクエリのデータ処理($/TB)は単価が小さく取り違えやすいため、本記事では具体額を載せていません。構造――「APIリクエストあたりの課金」+「インデックスサイズに応じたデータ処理課金(10万ベクトル超で単価低下)」――さえ押さえれば、コスト感の見通しは立ちます。ストレージ量の概算には、1次元あたり4バイト(1,024次元なら1件約4KB)という目安が便利です。
なお、AWSは「専用ベクトルDBと比較して保存・クエリの総コストを最大90%削減できる」とうたっています。これはAWSの主張値で、比較対象や前提ワークロードによって変わる数字です。「どんな構成でも9割安くなる」という意味ではありません。
ベクトルストアの選定軸 — どう選ぶか
ここが本記事の主戦場です。S3 Vectors は万能の置き換えではなく「適材適所」で効きます。「頻度の低い大量データを、安い層に逃がす」という発想が実務的です。代表的な3つの選択肢を並べてみましょう。
| 観点 | S3 Vectors | OpenSearch(Service / Serverless) | pgvector・専用ベクトルDB |
|---|---|---|---|
| 狙い | 大量・長期・低頻度。コスト最適 | 高QPS・低レイテンシのリアルタイム検索 | 用途特化(RDB併用や高性能) |
| レイテンシ | 低頻度で1秒未満 / 高頻度で約100ミリ秒以下 | サブ秒・高スループット | 製品・構成による |
| クエリ頻度 | 低頻度向き | 頻繁・常時アクセス向き | 用途依存 |
| コスト傾向 | 容量あたりが安い | 性能ぶんのプレミアム | 製品・構成依存 |
「QPS」はQueries Per Second(秒間クエリ数)です。ざっくり言えば、高頻度で叩くリアルタイム検索なら OpenSearch、大量データを安く長く持つなら S3 Vectors という棲み分けですね。pgvector(PostgreSQL の拡張)や Pinecone などの専用DBとの優劣は公式の対比数値がないため断定しませんが、「リアルタイム性 vs コスト・容量」の軸で自分の要件がどちら寄りかを見極めるのが安全です。
ハイブリッド階層設計という勘所
実務でいちばん現実的なのは、二者択一ではなく組み合わせです。AWSも推奨アーキテクチャに挙げるのが、ハイブリッドの階層設計です。大量のベクトルはまず S3 Vectors に低コストで保存し、最高性能が必要なベクトルだけを OpenSearch に「昇格」させる。需要の変化に応じて層の間で移す考え方ですね。
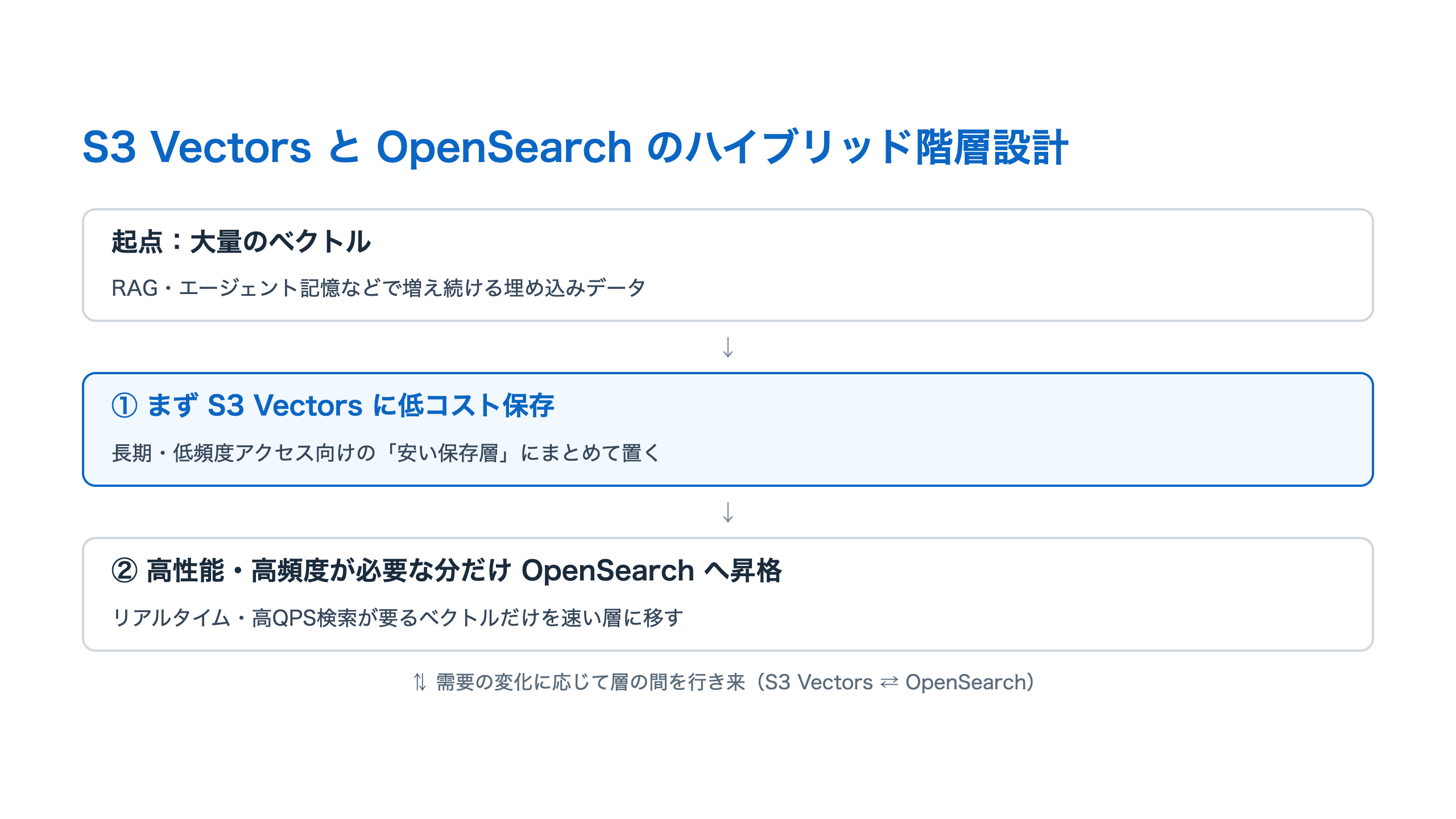
コスト試算もこの層の設計次第です。クエリ頻度が高ければクエリ課金が効き、低頻度ならストレージ中心になるので、「自分のクエリ頻度と、どの要素が支配的か」を先に把握するのが見積もりの近道です。
まとめ
ポイントは3つです。
- S3 Vectors = 大量・長期・低頻度向けの低コストなベクトル保存層。リアルタイム高QPSが要るなら OpenSearch、が基本の棲み分けです。
- 料金は3要素の従量課金(ストレージ/PUT/クエリ、いずれも参考値・公式要確認)。クエリのデータ処理単価は誤りやすい点に注意です。
- ハイブリッド階層設計が実務の勘所。安い層に大量保存し、性能が要る分だけ OpenSearch に昇格。AgentCore の Memory 層とも自然につながります。
RAG のデータ層は、ベクトル類似検索の S3 Vectors と、業務文脈で絞り込む S3 アノテーション を二本柱で設計すると噛み合います。あわせて、S3 Vectors を含む最近のAWSアップデートは AWS最新サービスの解説ハブ に横断的にまとめています。